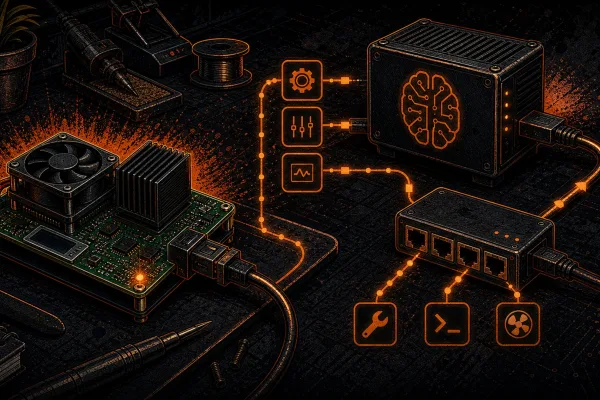
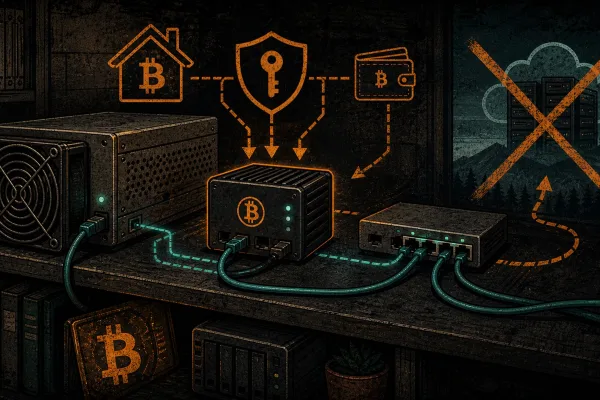
GPUs Are the New ASICs: Why AI Compute Will Decentralize Like Bitcoin Mining
AI compute is running the same concentrate-burn-distribute cycle as Bitcoin mining. GPUs go obsolete like ASICs, over-leveraged operators get burned, and the compute trickles down to the edge — ending in sovereign home mining and home AI inference.