Quick answer
Your self-hosted model's identity layer is still Web2 — username/password or API keys. Nostr answers three questions with its existing primitives: who the model talks to (keypair identity, not accounts), whether its output is genuine (signed events), and how to pay per prompt without an invoice (zaps). It composes with Open WebUI, Ollama, and llama.cpp.
Why identity matters for self-hosted AI
Two-thirds of this audience is already running local models. LM Studio on the laptop. Ollama on a home server. Open WebUI in front of a 3090. A few brave plebs running a quantized 70B on a stack of P40s because they refuse to send another token to OpenAI.
The hardware is solved. The models are solved (enough). What is not solved, at the pleb scale, is the identity layer of all this. Three practical questions:
- Who is this model talking to? Username + password is a Web2 answer to a Web3 problem. API keys are worse — they leak, they rotate, they tie you to a vendor.
- How do we verify what the model said? A hosted model’s output is today just a string on a screen. Nobody signed it. Nobody can prove the model actually produced it. Nobody can prove it has not been tampered with in transit or after the fact.
- How do we pay per prompt without accounts? If your friend wants to use your Ollama box, or your model wants to offer its tokens to the public, you need a way to bill that is not “send me a Stripe invoice.”
Nostr answers all three with its existing primitives — signed events, keypair identity, zaps — and it answers them in a way that composes with the rest of the pleb’s sovereign stack.
Bring Nostr identity to Open WebUI / LM Studio / Ollama
The three tools most plebs self-host are Open WebUI (by Timothy J. Baek and contributors — the ChatGPT-style front-end), Ollama (by the Ollama team — the model runtime), and llama.cpp (by Georgi Gerganov — the inference engine under most of it). LM Studio sits in the same slot as Open WebUI for desktop users. Shoulders of giants: none of this gets built without those projects, and they have done the hard work of making local inference a one-click affair.
What they all still default to is Web2 auth. Open WebUI ships with a local username/password system. LM Studio does not bother with auth because it assumes it is only ever on localhost. Ollama exposes an HTTP API with no auth at all until you stick a reverse proxy in front of it.
The pleb’s answer is to put an npub-auth shim in front of the inference endpoint. The pattern is simple and already shipping in the wild:
- Place a small reverse proxy in front of your Ollama / Open WebUI API (
nginx, Caddy, or a custom FastAPI/Express layer — pick what you know). - Require a NIP-98-style signed HTTP event on every request — a short-lived Nostr event that proves the caller controls a given
npub. - Optionally check the
npubagainst an allowlist. Only your own key. Only your friends. Only paid subscribers whose last zap is less than 30 days old.
No accounts. No database of hashed passwords. No rotating API keys. Just a signed request from a keypair you recognise.
The self-hosted AI primer covers the base stack; layer npub-auth on top once the box is running.
NIP-44 encrypted DMs as the transport
Here is where it gets elegant. Instead of building a custom chat UI in front of your model, you can use any Nostr client as the front-end and use encrypted DMs as the transport.
NIP-44 is the modern Nostr encrypted-DM spec (replacing the older NIP-04). ChaCha20-Poly1305, versioned, reviewed. Any compliant client — Amethyst, Damus, Coracle, 0xchat — can send and receive NIP-44 messages.
The pattern:
- Assign your AI agent a Nostr keypair. Its
npubbecomes the chatbot’s “handle” on the network. - A small bridge process subscribes to DMs addressed to that
npub, decrypts them with the agent’snsec, feeds the decrypted text into your local model, and replies by publishing an encrypted DM back to the sender. - From the user’s perspective, they are “DMing a bot” from their phone’s Nostr client. Under the hood, the “bot” is your Open WebUI / Ollama box sitting behind a reverse proxy in your closet.
You just built a private, end-to-end encrypted chat interface to your self-hosted model, from any device, with no apps to install beyond the Nostr client the user already has. And the only identity involved on either side is a keypair.
Zaps-for-prompts
Running inference costs electricity. If your rig is a 3090 or a pair of P40s in a Hashcenter, every hour of token generation is sats going out the door. The cleanest way to recover that cost — or to let friends use your box in exchange for value — is zaps-for-prompts.
The mechanic, using primitives you already have:
- Your inference endpoint declares a per-request price in sats (say, 10 sats per 1k output tokens).
- A caller sends a prompt. The endpoint returns a Lightning invoice — LNURL-pay, or a BOLT-11 generated on your own Lightning node.
- The caller pays. Invoice is marked as settled. Inference runs. Response returns.
- Optionally, the endpoint publishes a zap receipt to Nostr so there is a public record of the transaction — useful for reputation, useless for privacy, so make it opt-in.
This is just zaps repurposed as API billing. No Stripe. No KYC. No credit card on file. Any Lightning wallet with zap support can pay; any npub can be the billing account. A pleb in Buenos Aires running Mutiny can buy inference from a pleb in Lagos running Phoenix, and the whole transaction clears in two seconds without either of them meeting a fiat rail.
The obvious upgrade: prepaid balances keyed to npub. User zaps 10k sats up front, endpoint credits their npub with 10k sats of inference budget, subsequent requests just debit the balance until it drops to zero. Same trick BTCPay Server does for merchants, applied to tokens.
Signed model output
Every token your self-hosted stack produces can — and for agentic uses should — be wrapped in a signed Nostr event.
The pattern:
- The model operator has an
npub(their own, or a dedicated one per model). - After generating a response, the inference endpoint constructs a Nostr event of
kind 1(or a custom kind) containing the prompt hash, the model name + quantization, the output, and relevant metadata (temperature, seed, timestamp). - The event is signed with the operator’s
nsecand optionally published to a relay. - Anyone — the user, a third party, an auditor — can verify after the fact that the output came from that operator’s key and has not been altered.
This is cryptographic provenance on AI output. It does not prove the model is honest. It does not prove the operator is honest. But it makes the claim of what was said falsifiable, which is a huge upgrade over “screenshot on a forum.” Combined with reproducible builds of the model weights and quantizations, it is the foundation of an auditable agentic AI ecosystem.
The signed-output pattern is also the right answer for “is this post / image / summary AI-generated?” Instead of watermark hacks that get stripped, publish the output with a signature. If the signature checks out against a known agent npub, you know exactly which model produced it. If there is no signature, assume human (or unverified).
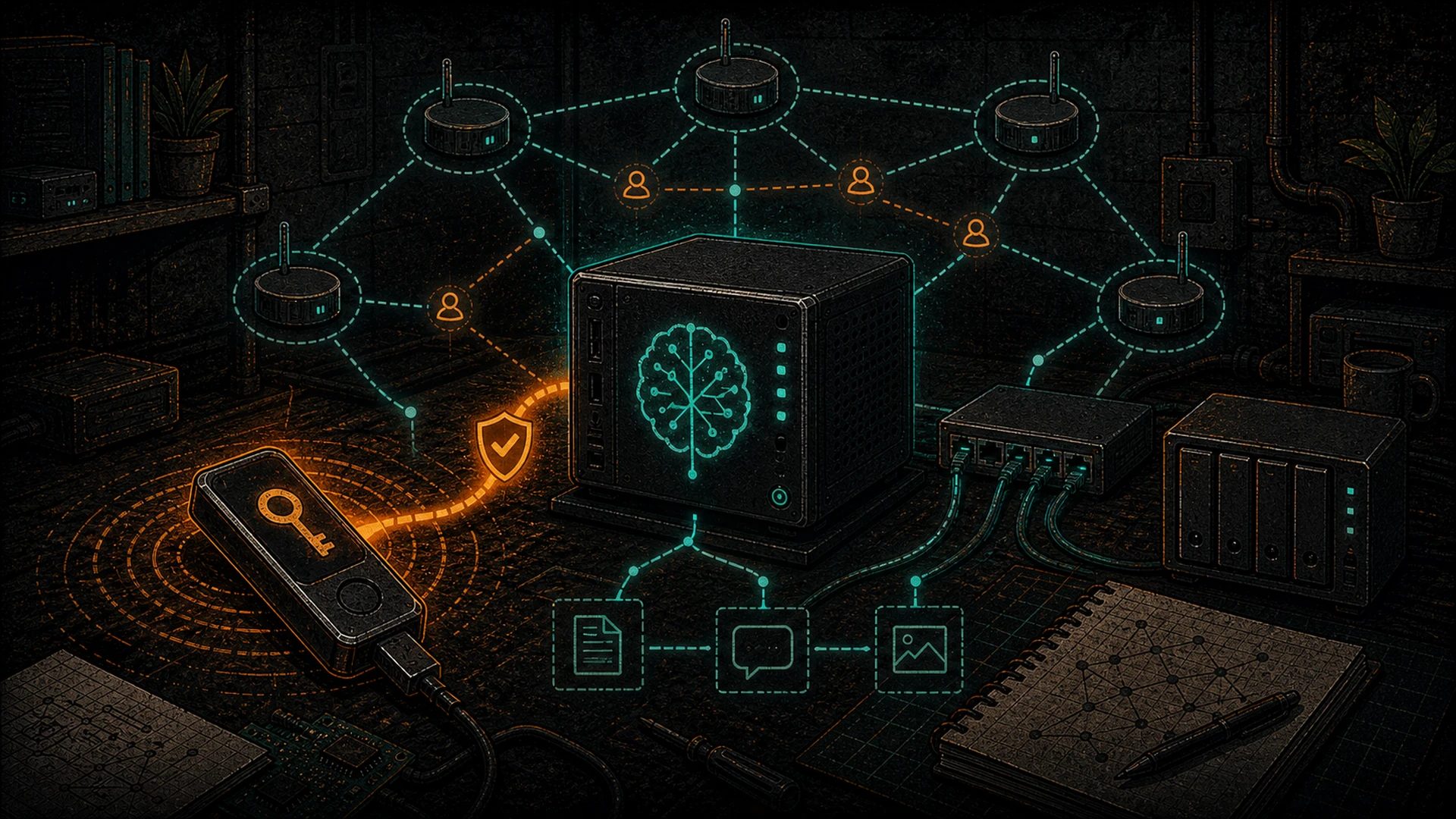
Sketch: minimal relay + agent topology
Here is the thinnest possible sovereign AI + Nostr stack that exercises all of the above.
[ user's phone (any Nostr client) ]
| encrypted DMs (NIP-44)
v
[ your self-hosted relay ] <-- from /run-your-own-nostr-relay-bitcoiners/
|
v
[ bridge process on your home server ]
- subscribes to DMs for agent's npub
- verifies caller npub is allowed (or paid)
- for paid: issues LNURL invoice via your LN node
|
v
[ Ollama / Open WebUI / llama.cpp ]
|
v
[ bridge signs response, publishes encrypted DM back ]Hardware: an old NUC or a Raspberry Pi 5 for the relay and bridge, a GPU box for inference. Both can be on the same LAN. Neither talks to OpenAI, Anthropic, Google, or Cloudflare for auth, billing, or transport. The whole thing runs on Bitcoin + Nostr primitives.
That is the full stack. It fits in a small home rack. It costs less than a used car. It is the Web3 moral equivalent of the LAMP stack, and the pleb gets to own every layer.
Future: agentic mining + Nostr identity for autonomous bots
Where this gets really interesting is when the “user” on the other side of the npub is not a human at all.
An autonomous miner agent — a DCENT_axe, a Bitaxe cluster, an agentic mining node — can carry its own keypair, sign its own telemetry events, receive zaps from humans who care about its output, pay its own electricity bill to its hashcenter operator, and negotiate with other agents. Nostr is the identity layer that makes that coherent. Lightning is the money layer. Bitcoin is the settlement layer. The mining hardware is the physical layer. All four pillars already exist; the composition is the work.
We are not there yet. We are close. The sovereign AI for Bitcoiners manifesto sketches the arc. This post is the single concrete step — “give your inference stack a Nostr identity today” — that starts making the bigger picture tractable.
Put an npub on your Ollama box. Let friends DM it. See what they build.
For more of the path: Nostr for Bitcoiners, Run your own Nostr relay, and the Sovereignty hub that ties the pillars together.
The sovereign stack: own every layer
Sovereignty is layered: Bitcoin for money, a local LLM for intelligence, mesh for connectivity, Nostr for identity, and your own power. Each piece is one more layer no single actor can switch off.